
step.ai: the quickest way to build reliable AI applications on Serverless while saving on compute
Charly Poly· 12/10/2024 · 6 min read
Inngest's functions are popular among developers deploying their applications on Serverless platforms such as Vercel. Its step.run() API enables developers to add state to Serverless Functions, overcome third-party rate limits and timeouts, and recover from failures with retries.
Our new step.ai.infer() API offloads all LLM requests to Inngest's infrastructure, removing all duration constraints when developing AI applications in Serverless environments.
In this article, we'll see how combining the step.run() and step.ai.infer() APIs is the quickest way to build reliable AI applications on Serverless while saving on compute.
step.run(): AI applications are workflows
Inngest Functions are composed of steps defined using the step.run() API. Each step is an independent cached and retriable part of your function, making your workflows durable (in other words, unbreakable).
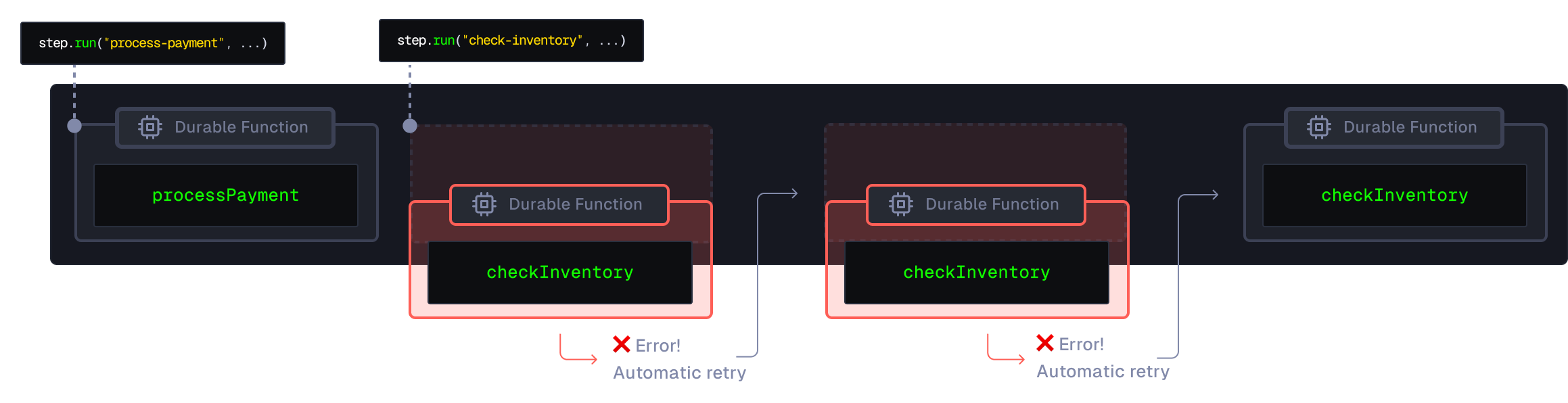
Building AI applications mainly consists of building workflows composed of 3 primary types of steps:
- Gather context for the LLM: Retrieve data, generate embeddings, preprocess user data (ex, uploaded files)
- Perform LLM calls: single-shot prompts, prompt chaining, or agentic workflows
- Process the generated results: save the generated result and trigger business-related logic (ex, sending notifications, bulk process data, etc.)
By using step.run() to build your AI workflows, each step of your workflow immediately benefits from automatic retries, throttling configuration, and caching:
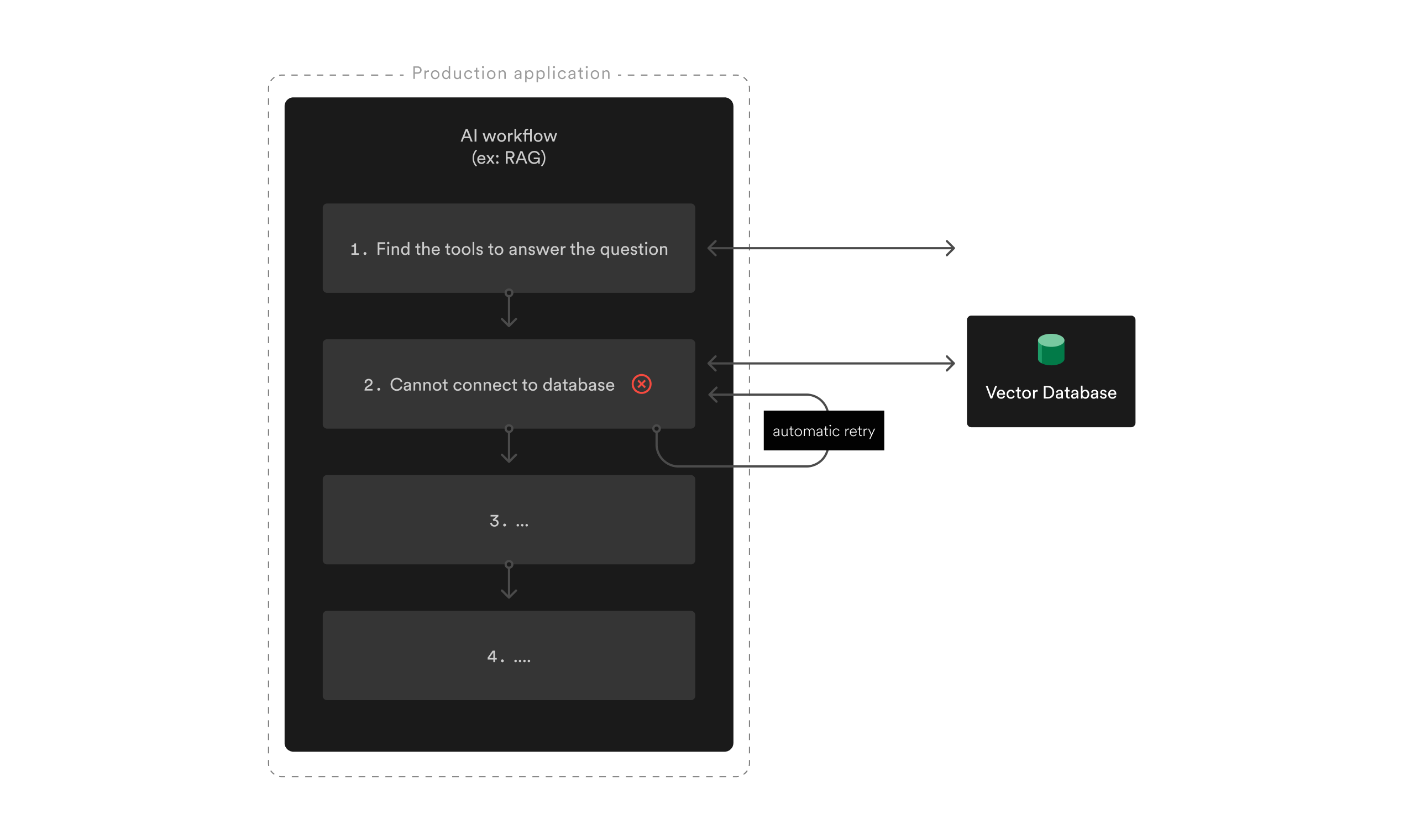
The interesting bit is that retrying the vector database step does not rerun the first LLM call, saving you some credits and Serveless compute time.
Here is an example from MegaSEO, an AI product built with Inngest to generate SEO-optimized articles:
This first index-page function demonstrates the pattern described above:
The first step retrieves the page content (using scraping).
The second step uses the first step result to index it into a vector database.
Here, a failure of the vector insert step won't trigger a new run of the first scraping step.
The second index-site function triggers the first index-page function in parallel for each website page.
Important note: each step.run() runs into a dedicated Serverless Function run, meaning that step.run() also helps to extend your Serverless Function's duration limit.
Running steps in parallel is simply achieved using Promise.all().
// index_functions.tsexport const indexPage = client.createFunction({ id: "index-page", concurrency: 10 },{ event: Events.INDEX_PAGE },async ({ event, step }) => {const { pageUrl } = event.data;const page = await step.run("get-page-content", async () => {return getPageContent(pageUrl);});await step.run("index-page", async () => {return saveToPinecone({ page });});});export const indexSite = client.createFunction({ id: "index-site" },{ event: Events.INDEX_SITE },async ({ event, step }) => {const { url } = event.data;const pages = await step.run("find-pages", async () => {return findPagesToIndex(url);});await Promise.all(pages.map(async (page) => {return step.invoke(`index-page-${page.url}`, {function: indexPage,data: { pageUrl: page.url },});}));});
// index_functions.tsexport const indexPage = client.createFunction({ id: "index-page", concurrency: 10 },{ event: Events.INDEX_PAGE },async ({ event, step }) => {const { pageUrl } = event.data;// The first step retrieves the page content (using scraping).const page = await step.run("get-page-content", async () => {return getPageContent(pageUrl);});// The second step uses the first step result to index it into a vector database.// Here, a failure of the vector insert step won't trigger a new run of the first scraping step.await step.run("index-page", async () => {return saveToPinecone({ page });});});export const indexSite = client.createFunction({ id: "index-site" },{ event: Events.INDEX_SITE },async ({ event, step }) => {const { url } = event.data;const pages = await step.run("find-pages", async () => {return findPagesToIndex(url);});// The second `index-site` function triggers the first `index-page` function in parallel for each website page.// Running steps in parallel is simply achieved using `Promise.all()`.await Promise.all(pages.map(async (page) => {return step.invoke(`index-page-${page.url}`, {function: indexPage,data: { pageUrl: page.url },});}));});
You can explore the complete AI workflow code in this article.
The above AI workflow demonstrates how the Inngest Function's step.run() API makes fetching context for LLM calls easier.
With few lines of code, MegaSEO built a complex and scalable AI workflow that can recover from external errors (ex, scraping or network issues) without performing unnecessary costly and slow step reruns.
Let's now see how to use the step.ai.infer() method can help you perform LLM requests without consuming Serverless compute or reaching the maximum duration limit.
step.ai.infer(): offloading slow LLM requests
Some AI patterns requiring long-running requests are challenging to adopt on Serverless, such as reasoning models like OpenAI o1, the ReAct pattern, or a multi-agent setup.
We recently released step.ai.infer() to solve this challenge:
export default inngest.createFunction({id: "generate-import-workflow",},{ event: "contacts.uploaded" },async ({ event, step }) => {const generatedStepsResult = await step.ai.infer("generate-workflow-steps",{model: step.ai.models.openai({ model: "gpt-4" }),body: {messages: [{role: "user",content: prompt(event.data.contactsFileContent),},],},});// ...})
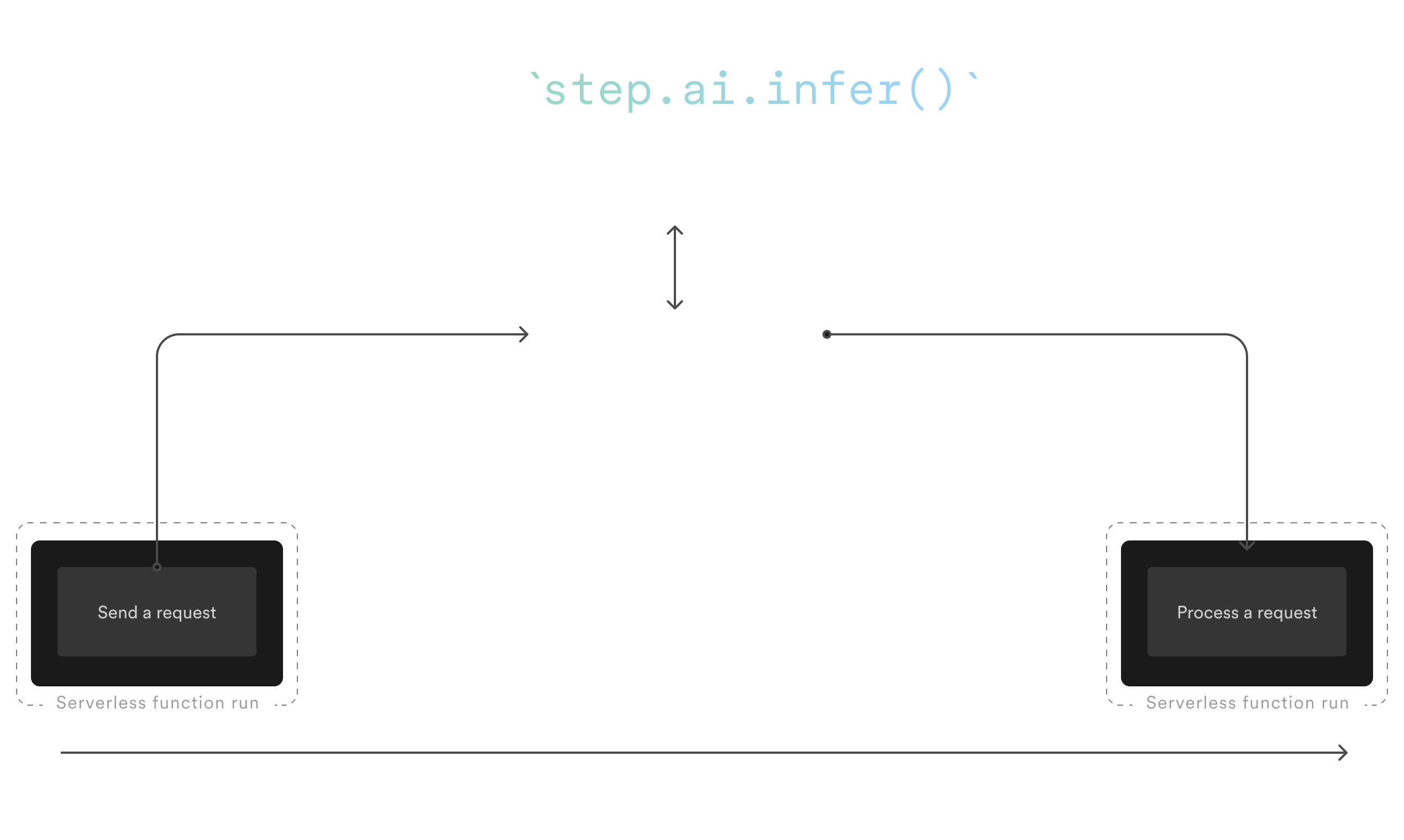
Performing an LLM call with step.ai.infer() pauses your workflow while the Inngest's servers perform the LLM request. Your workflow gets resumed when the LLM request is completed, saving the compute time usually used when an LLM call is done within a Serverless Function:

Let's review an example Next.js application that leverages the OpenAI o1 reasoning model and Inngest's step.ai.infer().
Our sample Next.js application, available on GitHub, uses OpenAI o1 to import contacts CSV files by dynamically creating Inngest workflows. OpenAI o1 gets prompted with the file and available workflow steps. In return, the LMM returns a valid workflow schema used to process the file:
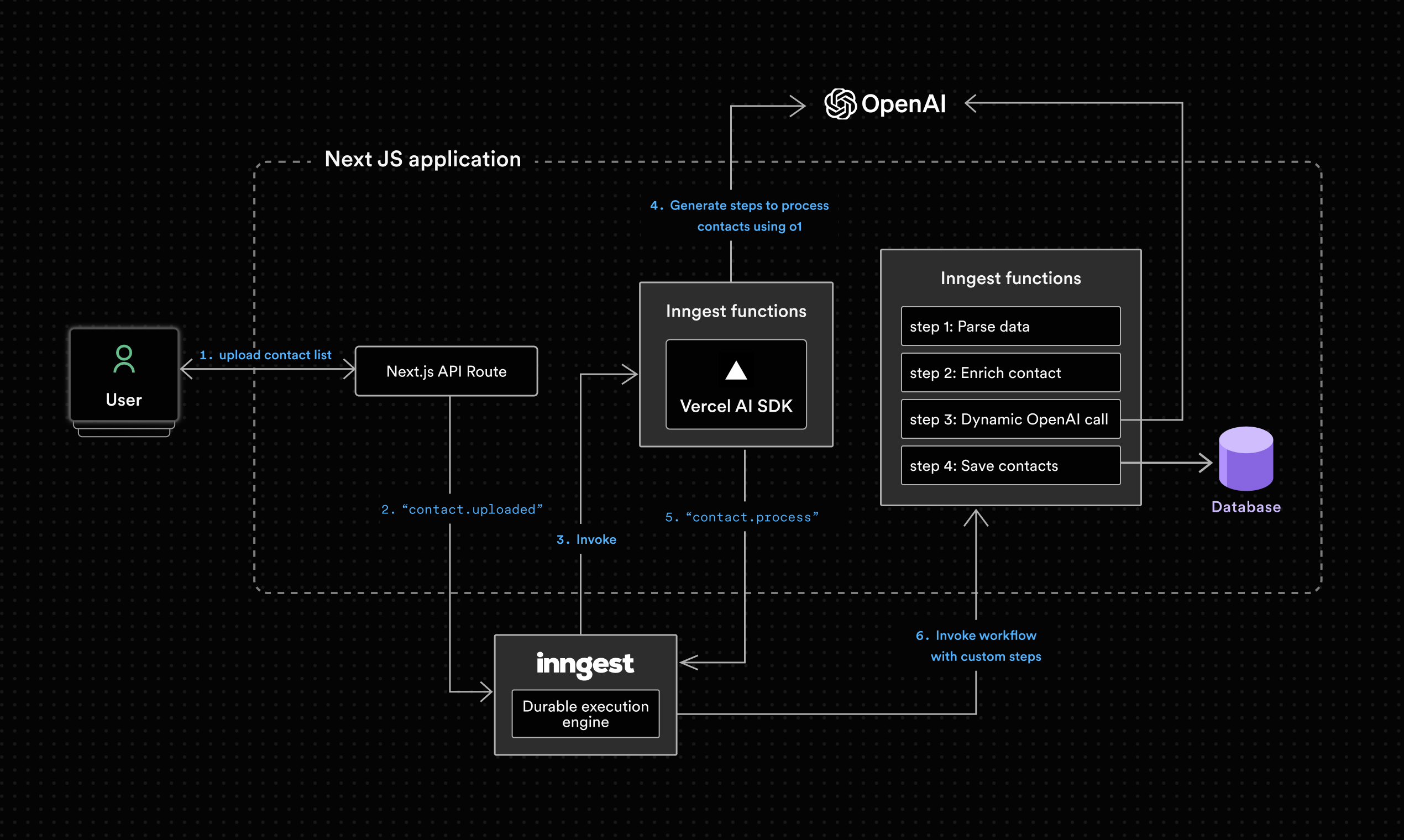
The initial call to the OpenAI o1 model can take multiple minutes, consuming Vercel Serverless computing while waiting for the LLM request and risking reaching the maximum duration limit.
Thankfully, this OpenAI call is performed using step.ai.infer(), removing any timeout and billing surge risks:
export default inngest.createFunction({id: "generate-import-workflow",throttle: {limit: 5000,period: "1m",},},{ event: "contacts.uploaded" },async ({ event, step }) => {const generatedStepsResult = await step.ai.infer("generate-workflow-steps",{model: step.ai.models.openai({ model: "gpt-4" }),body: {messages: [{role: "user",content: prompt(event.data.contactsFileContent),},],},});// ...})
Explore the complete project on GitHub and run it locally or deploy it on Vercel.
Conclusion
We're happy to continue to support developers building Serverless applications by enabling the creation of durable, retriable workflows with step.run() and the efficient offloading of LLM requests with step.ai.infer().
Whether you're building a complex SEO generation tool like MegaSEO or AI features for your application, you can now create sophisticated AI workflows without getting bogged down by Serverless constraints thanks to automatic retries, granular step management, compute cost savings, and the ability to handle long-running AI operations without hitting platform time limits.
As AI evolves, tools that simplify infrastructure complexity will become increasingly crucial for developers looking to build intelligent, reliable applications quickly and efficiently.